

一直想做一个关于SEO知识的系统梳理与总结,从搜索引擎的基本原理、网页的抓取收录与索引再到排名、点击与转化等的SEO全链路,将SEO知识的大方向包含在内,也是对自身SEO知识的一次巩固。
关于爬虫抓取,其实对于现在的SEOer来讲关注的比较少,一方面对于小型企业的网站来讲,关注重点更多的还是网站的内容优化以及外链,一般的爬虫抓取量已经够用,不是关注重点;另一方面,爬虫抓取的数据难以获取,这涉及到与技术和服务器运营方的协作。所以关于爬虫抓取的分析一般都应用于中大型网站。
本文会着重于搜索引擎关于抓取的基本原理,影响抓取的几个基本因素,爬虫抓取数据的分析以及抓取预算这个概念等进行讨论。
搜索引擎的基本原理
搜索引擎一方面要对海量数据(也就是互联网网页)进行获取/存储,另一方面也要快速准确地响应用户查询,而这一切的第一步就是抓取。通过多种类型的网络爬虫,搜索引擎可以发现未知的网页,并通过这些网页可以进一步挖掘更多网页。
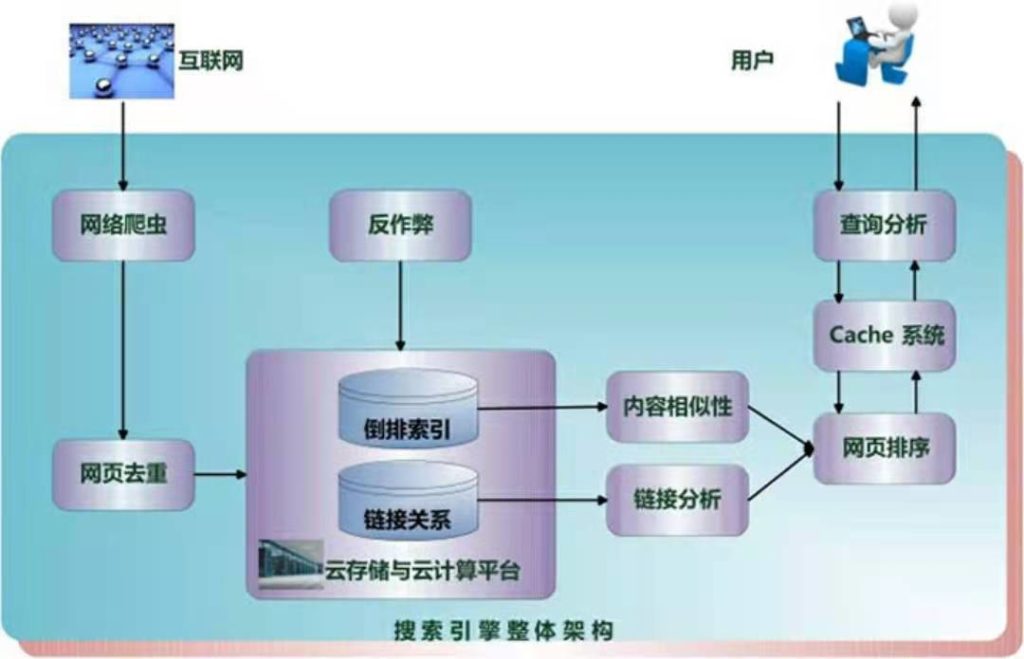
在获取网页数据后,搜索引擎需要对网页进行解析,抽取其主体内容,以及其中包含的链接及链接关系(为网页的相关性排序做准备),搜索引擎了解网页的这个过程叫收录与索引,谷歌的索引是一个拥有很多很多台计算机的巨大数据库。
当用户输入关键词进行查询时,搜索引擎会判断用户的真正搜索意图,根据多种因素(主要是内容相关度与网页质量度)来尝试对相关的网页进行排序,这个过程中你的网页就有机会得到展示与点击。当然现在谷歌以及百度都会参考个人的地理位置以及设备等信息,给出最优的搜索结果,所以以后的搜索会越来越个性化。
影响爬虫抓取的因素
- Robos文件,通过robos文件我们可以规定搜索引擎抓取或不能抓取什么目录下以及什么参数的url;
- 服务器压力,有时候服务器压力过大,爬虫会减少抓取;或服务器出现问题,抓取返回错误代码,也会影响抓取;
- 网页质量,质量包括内容,模板,链接,核心网页指标等多方面内容,显然高质量的网页与内容是谷歌更愿意抓取的;
- 网页更新频率,搜索引擎需要保证时效性,所以会重点关注新内容的抓取,不光是新发布的内容,也包括修改完善的旧内容;
- 网站权威性,可以理解为网站权重,百度的抓取有一个大站优先策略,倾向于认为大型网站的页面质量更高,这一点在谷歌应该也适用;
影响爬虫抓取的因素有很多,但并不是抓取的越多越好,我们的目的应该时让搜索引擎抓取我们想让抓取的网页,并且这个抓取过程是简单的,对服务器也不会造成压力。
爬虫抓取数据的分析
关于爬虫抓取数据分析方面的工具,国内最早且比较有名的就是张国平的光年日志分析工具,不过在我开始做SEO的时候早就没这个东西了,一些专业的SEO人员可能都是通过自己开发的代码程序进行分析,但我这里推荐一款爬虫日志分析工具:尖叫青蛙(screamingfrog),很实用也很适合非技术型的SEO人员。
关于爬虫抓取数据的分析,作用主要有两个,一个是根据异常反馈,查看并及时修补网站目前存在的抓取等方面的技术问题,另一个是日常监测,发现网站目前存在的增长机会。
关于爬虫抓取数据的分析,主要会涉及到以下方面:
- 抓取总时间与抓取总量
- 不重复抓取数量
- 所有状态码数量
- 各个目录或某个目录的抓取量
- 404状态码的页面抓取量
- 抓取总字节数
- 每个IP下对应URL的抓取次数
以我司网站为例,我发现网站的整体索引率较低,通过查看爬虫抓取日志数据,发现近一半的抓取量都消耗在了AMP页面,但AMP页面带来流量占比极少,这其实就压缩了其他页面的被抓取机会,并降低了索引率。但我们还需要进一步判断AMP页面存在的价值,决定是否将其下线。
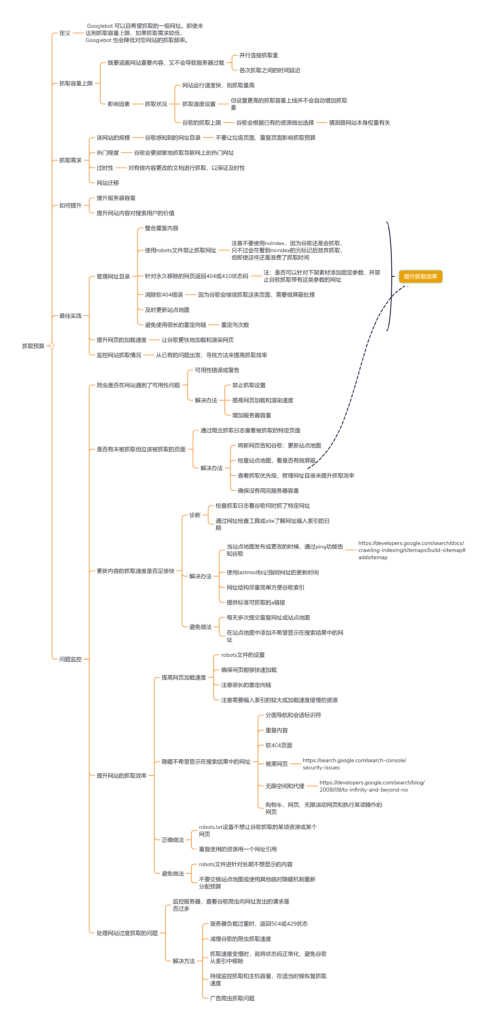
抓取预算:如何提升抓取效率
对于搜索引擎来讲,互联网存在着近乎无限的空间与页面,不可能对所有页面都进行抓取;同时对各个网站来说,抓取网站所有页面既有可能对服务器造成负担,同时也会让搜索引擎无法找到你的重点页面与优质页面。所以这个时候就要提出一个概念:抓取预算。
所谓抓取预算,就是将引导爬虫到你最想被抓取的页面,并保证其都能抓取且不会影响网站正常运行,这一点对于有着数百万甚至上千万页面的大型网站尤为重要。我们需要优化和提升抓取预算,来提升爬虫的爬虫效率,进而提高索引率。
- 善用robots文件,通过robos文件告诉谷歌你不想被抓取的url或目录,这其中包括隐私页面、动态参数页面、重复页面等;
- 及时更新站点地图,不仅是及时添加新网页的URL,并且对之前过时的、重定向的或者错误的URL进行清理替换,确保垃圾页面不会被抓取;
- 减少重定向的使用,谷歌提倡一个页面重定向不要超过五次,但实际是越少越好;
- 提高网页的加载速度,这样能让谷歌更快速地读取你的网页,并且读取到更多的内容;
- 监控网站的爬虫抓取数据,更好地了解网站出现的抓取变化,并及时提出修改策略。
抓取预算思维导图
总结
SEO爬虫抓取篇其实涉及到的专业知识和技术原理很多,如果懂技术,也能对爬虫数据做出更细致的分析,这也是我欠缺的地方(还是要多学习呀),所以写此文还是有些吃力的,也拖了好些天。
由于SEO涉及的因素与变量太多,有时候看到流量数据的异常也无法准确分析,这时候看看爬虫抓取的数据吧,或许你会得到解答(也可能是更加困惑,嘿嘿)。
以上