

最近在学习曾老师的《适合运营推广的Python技能课》,以前总尝试着学习Python,但总是因为无法落地到实践中而不了了之,而这次课程的学习除了基础知识就是应用案例,很具有实操性,也让我对技术结合工作有了新的认知。
刚好这两天在研究站点素材的标题标签的生成,做竞品标题的词频和词性分析是不可少的,而这两者都可以借助Python完成。
英文句子的分词
批量获取竞品素材的标题是通过screaming frog完成的,这不是本文讨论的重点,也就不赘述了。
得到标题后可以通过工具:wordart 获取英文单词的词频,使用工具的好处是它有一个专业的过滤词库,可以过滤掉绝大多数无意义的词,但坏处是只能获取前1000个单词的词频,如果数据量特别大,那么使用工具就不太合适了。
因此整合网上的代码,我做的工具如下:
#引入pandas库
import pandas as pd
#读取过滤词库
with open('excludes.txt','r',encoding='utf-8') as file:
excludes_list = file.read().split('\n')
#清洗英文文本
def getText():
txt = open("music.txt",encoding='utf-8').read()
txt = txt.lower()
for i in '!"“”#$%&()*+,-./:;<=>?@[\]^_‘{|}~':
txt = txt.replace(i, " ")
return txt
#统计词频
EngTxt = getText()
words = EngTxt.split()
counts = {}
for word in words:
if word in excludes_list:
continue
else:
counts[word] = counts.get(word, 0) + 1
items = list(counts.items())
items.sort(key=lambda x: x[1], reverse=True)
for i in range(150):
word, count = items[i]
print("{0:<10}{1:>5}".format(word, count))
#存储到csv文件
pd.DataFrame(items).to_csv("test.csv")可以根据自身需要扩充过滤词库,得到更精准的结果。
英文单词的词性分析
作为Python初学者,最好的老师就是百度或谷歌,搜索得知分析自然语言处理一般都使用nltk库,而词性的分析可以通过pos_tags获取。最终我的代码如下:
#引入nltk库
import nltk,csv
import pandas as pd
#打开关键词列表
with open('keyword.txt','r',encoding='utf-8') as file:
list = file.read().split('\n')
#将关键词列表转化为字符串
list1=''
for i in list:
list1=list1+str(i)
list1+=' '
#将关键词转为小写
list1 = list1.lower()
#词性区分
tokens = nltk.word_tokenize(list1)
pos_tags = nltk.pos_tag(tokens)
# print(pos_tags)
#存储到csv文件(元组)
pd.DataFrame(pos_tags).to_csv("test.csv")这里遇到了几个问题,花费了不少时间解决。
1、nltk库的引入
首先是nltk库的引入,并不是在cmd输入pip install nltk就能解决,想要完整地安装nltk,需要通过以下代码实现:
import nltk
nltk.download()可以通过上述代码打开python进行下载安装,需要注意的是,下载需要打开科学上网,并且安装在C盘,不然你可能安装了一晚上都不成功。
2、列表与字符串的转换
因为我是抄别人的代码,原代码是简单分析一句话,也就是字符串,但我需要的是分析一个单词列表,需要先将列表转换为字符串才能继续进行。
3、单词的过滤
单词的特殊符号、大小写都会影响词性判断,由于我是使用工具得到的单词列表,首字母都为大写,所以出来的词性都是专有名词,这让我一度怀疑这个库有问题(有问题的只可能是我),后来先分析了一部分单词,才知道是大小写的问题。
4、单词、词性数据的存储
虽然我得到了数据,但这个数据并不是一列一列的,不够清晰明了,方便使用,所以保存也是一个问题。我先print了pos_tags,发现都是由元组构成,所以百度搜索元组数据的csv存储,最终知道了通过pandas库做数据处理,只需要一行代码就可以把元组数据存储下来。
最终结果:
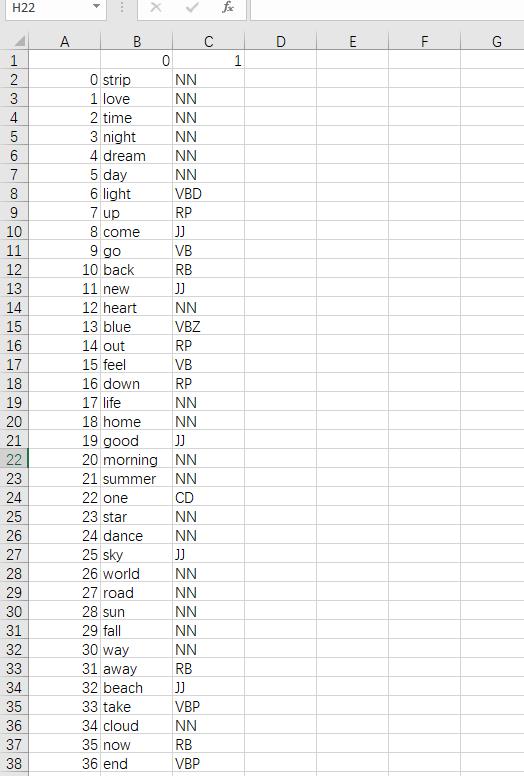
注:过滤词库、英文词性表
因为这两个都比较长,所以我放在石墨文档里,有兴趣的可以看看:
https://shimo.im/sheets/2wAlXmRZovfVKEAP/Rje0r
以上