

最近发现,很多收录量特别大的站点都有做面向爬虫抓取的静态页面,和用户看到的页面是有差异的,但url是一样的,这是一个蛮有意思的点,所以用这篇文章聊一下。
怎么看爬虫抓取页面
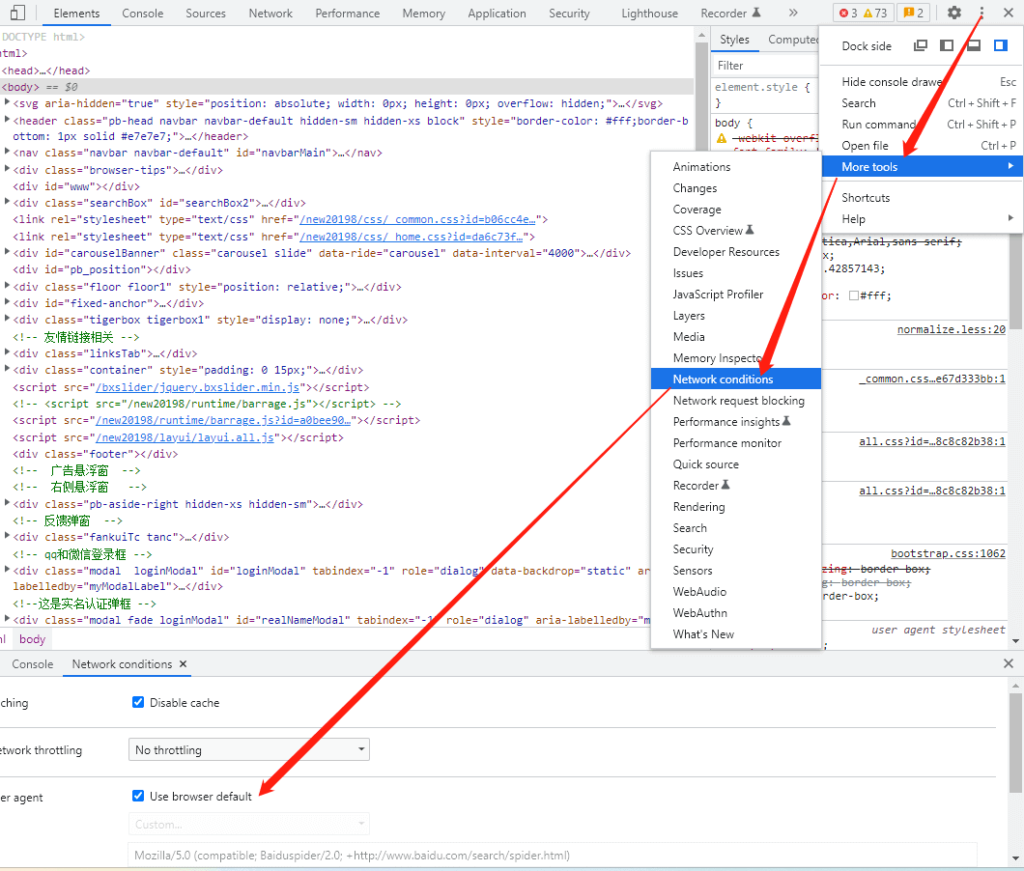
首先按F12打开开发者工具,点击右上角的三个点,选择More tools,再选择Network conditions,更改User agent,谷歌浏览器可以选择谷歌爬虫,然后再刷新网页即可。
如果是模拟百度爬虫抓取页面,需要搜索一下百度爬虫的User agent,填入输入框,再刷新页面就可以了。
关于百度爬虫的UA在网上一搜有很多,我这个截图里的是:
Mozilla/5.0 (compatible; Baiduspider/2.0; +<a href="http://www.baidu.com/search/spider.html">http://www.baidu.com/search/spider.html</a>)
关于谷歌爬虫的UA可以查看谷歌官方文档:
https://developers.google.com/search/docs/crawling-indexing/overview-google-crawlers
案例
以图片行业的摄图网为例,这个网站的收录量接近3亿了,网站的SEO优化可以说做了相当多的工作,但这不是今天讨论的重点。
我们讨论的重点还是网页的分层处理,通过上述方法查看该网站用户层和爬虫层的页面分别如下图:
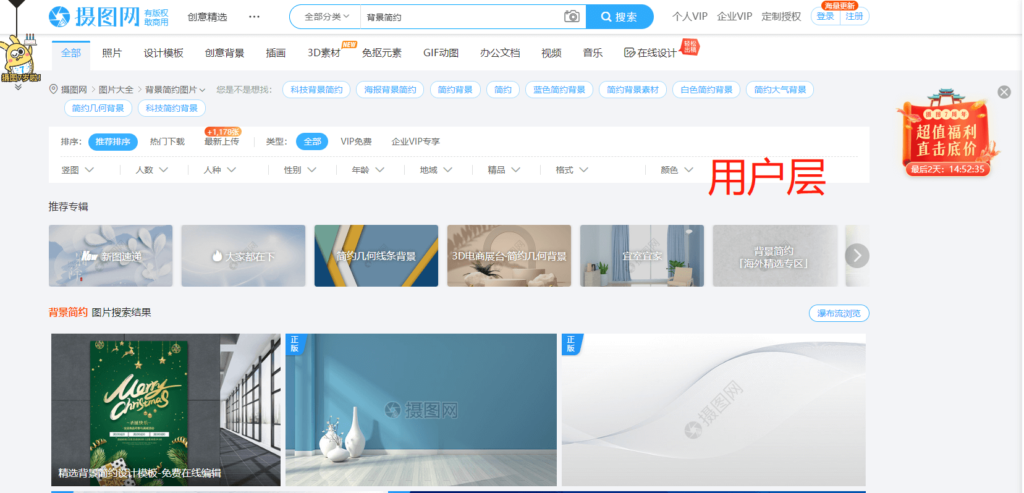
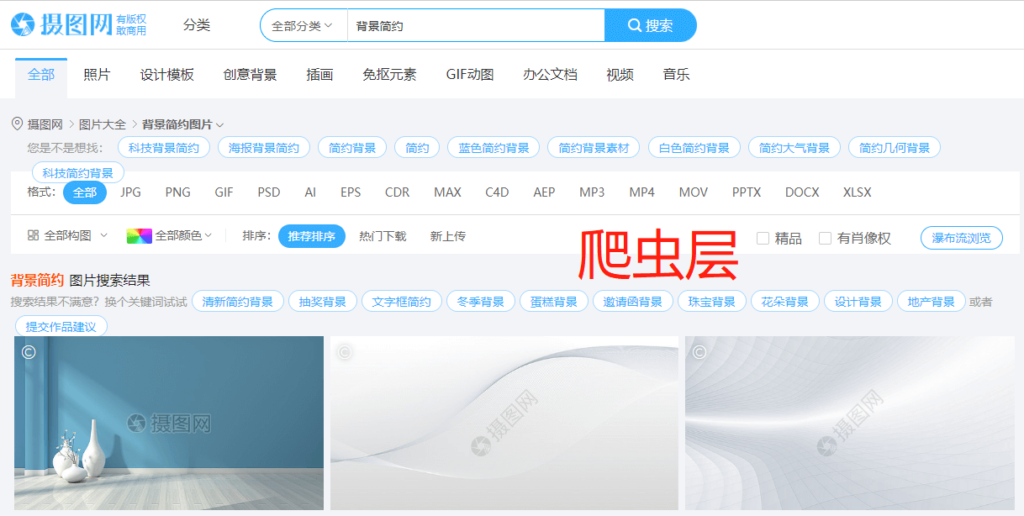
可以看到在用户层,页面信息丰富,包括弹窗、营销信息、导航等,满足了用户需要以及网站促销的需要;而在爬虫层则省去了这部分信息,并且把原本网页底部的相关搜索移到了首屏,更方面爬虫抓取内链。
网页分层的目的和好处
对于网站来讲,用户有两类,一是搜索引擎的爬虫,二是真实访客用户,做SEO工作也就是要搭建好这两类用户的桥梁,具体方法是通过识别UA请求头来实现,针对用户要优化体验、提升转化率,针对爬虫要方便抓取,提升效率。
好处:
①避免了与其他部门的冲突,比如产品经理要考虑的用户体验,运营部门要考虑的促销转化,这些都可以放到用户层做处理,而SEO只需要考虑爬虫层的优化;
②爬虫层简洁、无弹窗的页面,保证了页面是利于爬虫抓取和分析的,提升了抓取效率,对于SEO流量的增长是有帮助的;
③用户层内容信息丰富,对于提升网站的转化率是有帮助的;
是否会引起搜索引擎惩罚
不会,首先从实际效果来看,摄图网通过这种方式实现了接近三亿的收录量,显然是没有被百度惩罚的;其次这种方式做到了主体内容不变,这就不会被判定为作弊。
什么是主体内容呢?如上截图就是搜索页的主体部分的图片内容以及内链,在主体内容不更改的情况,我们所做的工作都是为了促进爬虫的快速抓取,这怎么能说是作弊呢。
思考
关于这个思路其实之前看的一篇文章讲的更透彻,并且是应用在谷歌爬虫的站点,可参考:
http://www.zhidaow.com/post/googlebot-seo-2021
这种方法对于大型站点是可借鉴的并且是可实现的,对于优化爬虫抓取、减轻服务器压力、提升网站收录进而提升流量都是有帮助的,但是对于小型站点的参考意义就不是很大了,因为一个只有一两百网页的站点,根本不可能涉及到抓取预算的问题。
以上